Notes about FoundationDB

Notes About is a blogpost serie you will find a lot of links, videos, quotes, podcasts to click on about a specific topic. Today we will discover FoundationDB.
🔗Overview of FoundationDB
As stated in the official documentation:
FoundationDB is a distributed database designed to handle large volumes of structured data across clusters of commodity servers. It organizes data as an ordered key-value store and employs ACID transactions for all operations. It is especially well-suited for read/write workloads but also has excellent performance for write-intensive workloads.
It has strong key points:
- Multi-model data store
- Easily scalable and fault tolerant
- Industry-leading performance
- Open source.
From a database dialect, it provides:
- strict serializability(operations appear to have occurred in some order),
- external consistency(For any two transactions, T1 and T2, if T2 starts to commit after T1 finishes committing, then the timestamp for T2 is greater than the timestamp for T1).
🔗The story
FoundationDB started as a company in 2009, and then has been acquired in 2015 by Apple. It was a bad public publicity for the database as the download were removed.
On April 19, 2018, Apple open sourced the software, releasing it under the Apache 2.0 license.
🔗Tooling before coding
🔗Flow
From the Engineering page:
FoundationDB began with ambitious goals for both high performance per node and scalability. We knew that to achieve these goals we would face serious engineering challenges that would require tool breakthroughs. We’d need efficient asynchronous communicating processes like in Erlang or the Async in .NET, but we’d also need the raw speed, I/O efficiency, and control of C++. To meet these challenges, we developed several new tools, the most important of which is Flow, a new programming language that brings actor-based concurrency to C++11.
Flow is more of a stateful distributed system framework than an asynchronous library. It takes a number of highly opinionated stances on how the overall distributed system should be written, and isn’t trying to be a widely reusable building block.
Flow adds about 10 keywords to C++11 and is technically a trans-compiler: the Flow compiler reads Flow code and compiles it down to raw C++11, which is then compiled to a native binary with a traditional toolchain.
Flow was developed before FDB, as stated in this 2013's post:
FoundationDB founder here. Flow sounds crazy. What hubris to think that you need a new programming language for your project? Three years later: Best decision we ever made.
We knew this was going to be a long project so we invested heavily in tools at the beginning. The first two weeks of FoundationDB were building this new programming language to give us the speed of C++ with high level tools for actor-model concurrency. But, the real magic is how Flow enables us to use our real code to do deterministic simulations of a cluster in a single thread. We have a white paper upcoming on this.
We've had quite a bit of interest in Flow over the years and I've given several talks on it at meetups/conferences. We've always thought about open-sourcing it... It's not as elegant as some other actor-model languages like Scala or Erlang (see: C++) but it's nice and fast at run-time and really helps productivity vs. writing callbacks, etc.
(Fun fact: We've only ever found two bugs in Flow. After the first, we decided that we never wanted a bug again in our programming language. So, we built a program in Python that generates random Flow code and independently-executes it to validate Flow's behavior. This fuzz tester found one more bug, and we've never found another.)
A very good overview of Flow is available here and some details here.
🔗Simulation-Driven development
One of Flow’s most important job is enabling Simulation:
We wanted FoundationDB to survive failures of machines, networks, disks, clocks, racks, data centers, file systems, etc., so we created a simulation framework closely tied to Flow. By replacing physical interfaces with shims, replacing the main epoll-based run loop with a time-based simulation, and running multiple logical processes as concurrent Flow Actors, Simulation is able to conduct a deterministic simulation of an entire FoundationDB cluster within a single-thread! Even better, we are able to execute this simulation in a deterministic way, enabling us to reproduce problems and add instrumentation ex post facto. This incredible capability enabled us to build FoundationDB exclusively in simulation for the first 18 months and ensure exceptional fault tolerance long before it sent its first real network packet. For a database with as strong a contract as the FoundationDB, testing is crucial, and over the years we have run the equivalent of a trillion CPU-hours of simulated stress testing.
A good overview of the simulation can be found here. You can also have a look at this awesome talk!
Simulation has been made possible by combining:
- Single-threaded pseudo-concurrency,
- Simulated implementation of all external communication,
- determinism.
Here's an example of a testfile:
testTitle=SwizzledCycleTest
testName=Cycle
transactionsPerSecond=5000.0
testDuration=30.0
expectedRate=0.01
testName=RandomClogging
testDuration=30.0
swizzle = 1
testName=Attrition
machinesToKill=10
machinesToLeave=3
reboot=true
testDuration=30.0
testName=Attrition
machinesToKill=10
machinesToLeave=3
reboot=true
testDuration=30.0
testName=ChangeConfig
maxDelayBeforeChange=30.0
coordinators=autoThe test is splitted into two parts:
-
The goal, for example doing transaction pointing to another with thousands of transactions per sec and there should be only 0.01% of success.
-
What will be done to try to prevent the test to succeed. In this example it will at the same time:
- do random clogging. Which means that network connections will be stopped (preventing actors to send and receive packets). Swizzle flag means that a subset of network connections will be stopped and bring back in reverse order, 😳
- will poweroff/reboot machines (attritions) pseudo-randomly while keeping a minimal of three machines, 🤯
- change configuration, which means a coordination changes through multi-paxos for the whole cluster. 😱
Keep in mind that all these failures will appears at the same time! Do you think that your current datastore has gone through the same test on a daily basis? I think not.
Applications written using the FoundationDB simulator have hierarchy: DataCenter -> Machine -> Process -> Interface. Each of these can be killed/freezed/nuked. Even faulty admin commands fired by some DevOps are tested!
🔗Known limitations
Limitations are well described in the official documentation.
🔗Recap
An awesome recap is available on the Software Engineering Daily podcast:
FoundationDB is tested in a very rigorous way using what's called a deterministic simulation. The reason they needed a new programming language to do this, is that to get a deterministic simulation, you have to make something that is deterministic. It's kind of obvious, but it's hard to do.
For example, if your process interacts with the network, or disks, or clocks, it's not deterministic. If you have multiple threads, not deterministic. So, they needed a way to write a concurrent program that could talk with networks and disks and that type of thing. They needed a way to write a concurrent program that does all of those things that you would think are non-deterministic in a deterministic way.
So, all FoundationDB processes, and FoundationDB, it's basically all written in Flow except a very small amount of it from the SQLite B-tree. The reason why that was useful is that when you use Flow, you get all of these higher level abstraction that let what you do what feels to you like asynchronous stuff, but under the hood, it's all implemented using callbacks in C++, which you can make deterministic by running it in a single thread. So, there's a scheduler that just calls these callbacks one after another and it's very crazy looking C++ code, like you wouldn't want to read it, but it's because of Flow they were able to implement that deterministic simulation.
🔗The Architecture
According to the fdbmonitor and fdbserver:
The core FoundationDB server process is
fdbserver. Eachfdbserverprocess uses up to one full CPU core, so a production FoundationDB cluster will usually run N such processes on an N-core system.
To make configuring, starting, stopping, and restarting fdbserver processes easy, FoundationDB also comes with a singleton daemon process,
fdbmonitor, which is started automatically on boot.fdbmonitorreads thefoundationdb.conffile and starts the configured set of fdbserver processes. It is also responsible for starting backup-agent.
The whole architecture is designed to automatically:
- load-balanced data and traffic,
- self-healing.
🔗Microservices
A typical FDB cluster is composed of different actors which are describe here.
The most important role in FDB is the Coordinator, it uses Paxos to manage membership on a quorum to do writes. The Coordinator is mostly only used to elect some peers and during recovery. You can view it as a Zookeeper-like stack.
The Coordinator starts by electing a Cluster Controller. It provides administratives informations about the cluster(I have 4 storage processes). Every process needs to register to the Cluster Controller and then it will assign roles to them. It is the one that will heart-beat all the processes.
Then a Master is elected. The Master process is reponsible for the data distribution algorithms. Fun fact, the mapping between keys and storage servers is stored within FDB, which is you can actually move data by running transactions like any other application. He is also the one providing read versions and version number internally. He is also acting as the RateKeeper.
The Proxies are responsible for providing read versions, committing transactions, and tracking the storage servers responsible for each range of keys.
The Transaction Resolvers are responsible determining conflicts between transactions. A transaction conflicts if it reads a key that has been written between the transaction’s read version and commit version. The resolver does this by holding the last 5 seconds of committed writes in memory, and comparing a new transaction’s reads against this set of commits.
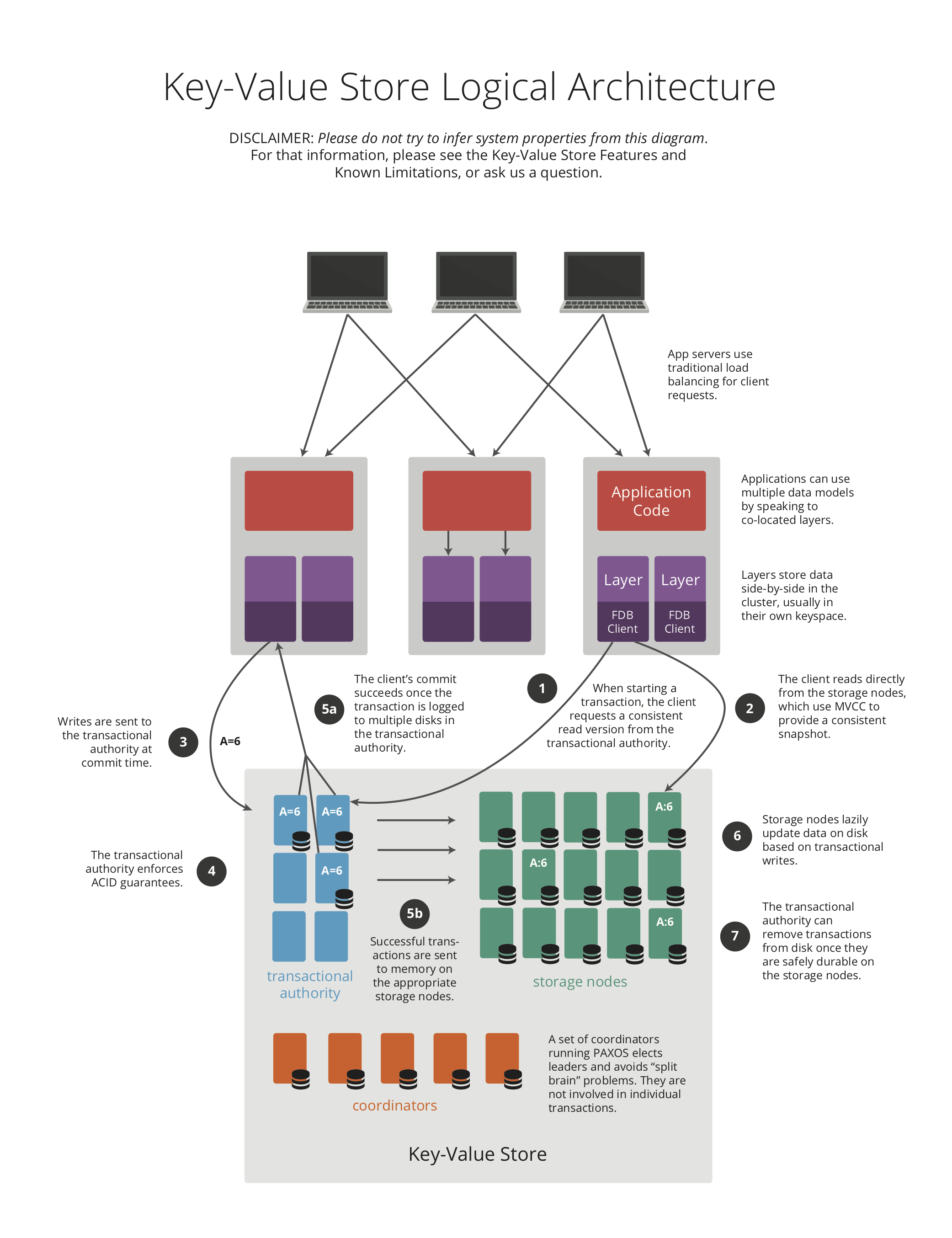
🔗Read and Write Path
🔗Read Path
- Retrieve a consistend read version for the transaction
- Do reads from a consistent MVCC snapshot at that read version on the storage node
🔗Write Path
- client is sending a bundle to the
proxycontaining:- read version for the transaction
- every readen key
- every mutation that you want to do
- The proxy will assign a
Commit versionto a batch of transactions.Commit versionis generated by theMaster - Proxy is sending to the resolver. This will check if the data that you want to mutate has been changed between your
read Versionand yourCommit version. They are sharded by key-range. - Transaction is made durable within the
Transaction Logsbyfsyncing the data. Before the data is even written to disk it is forwarded to thestorage serversresponsible for that mutation. Internally,Transactions Logsare creating a stream perStorage Server. Once thestorage servershave made the mutation durable, they pop it from the log. This generally happens roughly 6 seconds after the mutation was originally committed to the log. Storage serversare lazily updating data on disk from theTransaction logs. They are keeping new write in-memory.Transaction Logsis responding OK to the Proxy and then the proxy is replying OK to the client.
You can find more diagrams about transactions here.
🔗Recovery
Recovery processes are detailled at around 25min.
During failure of a process (Except storage servers), the systems will try to create a new generation, so new Master, proxies, resolvers and transactions logs. New master will get a read version from transactions logs, and commit with Paxos the fact that starting from Read version, the new generation is the one in charge.
Storage servers are replicating data on failures.
🔗The 5-second transaction limit
FoundationDB currently does not support transactions running for over five seconds. More details around 16min but the tl;dr is:
- Storage servers are caching latest read in-memory,
- Resolvers are caching the last 5 seconds transactions.
🔗Ratekeeper
More details around 31min but the tl;dr is that when system is saturated, retrieving the Read version is slowed down.
🔗Storage
A lot of information are available in this talk:
memoryis optimized for small databases. Data is stored in memory and logged to disk. In this storage engine, all data must be resident in memory at all times, and all reads are satisfied from memory.SSDStorage Engine is based on SQLite B-TreeRedwoodwill be a new storage engine based on Versioned B+Tree
🔗Developer experience
FoundationDB’s keys are ordered, making tuples a particularly useful tool for data modeling. FoundationDB provides a tuple layer (available in each language binding) that encodes tuples into keys. This layer lets you store data using a tuple like (state, county) as a key. Later, you can perform reads using a prefix like (state,). The layer works by preserving the natural ordering of the tuples.
Everything is wrapped into a transaction in FDB.
You can have a nice overview by reading the README of tsdb-layer, an experiment combining Time Series and FoundationDB: Millions of writes/s and 10x compression in under 2,000 lines of Go.
🔗FDB One more things: Layers
🔗Concept of layers
FDB is resolving many distributed problems, but you still need things like security, multi-tenancy, query optimizations, schema, indexing.

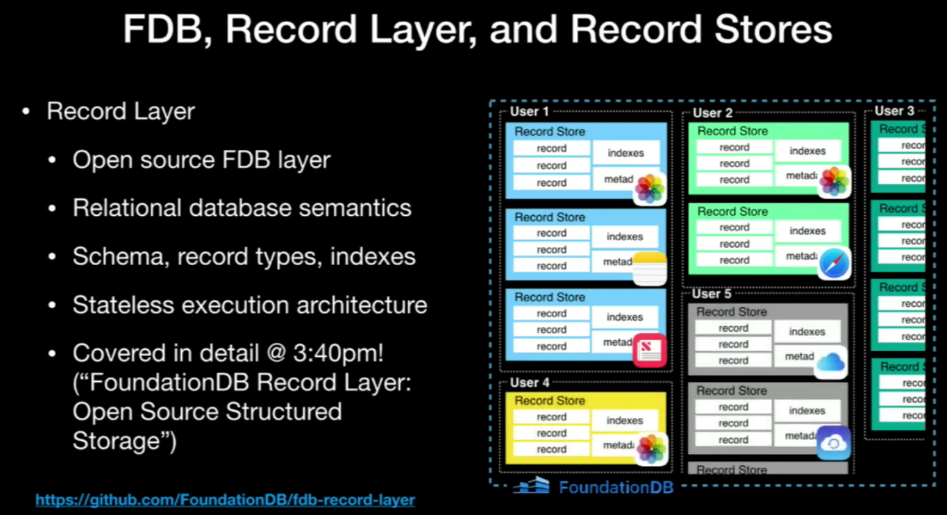
Layers are designed to develop features above FDB. The record-layer provided by Apple is a good starting point to build things above it, as it provides structured schema, indexes, and (async) query planner.
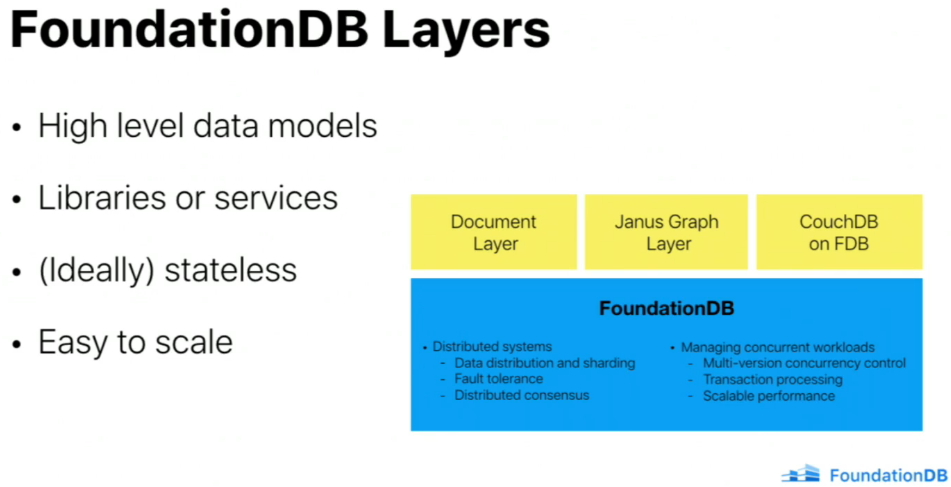
The record-layer provided by Apple is a good starting point to build things above it, as it provides structured schema, indexes, and (async) query planner.
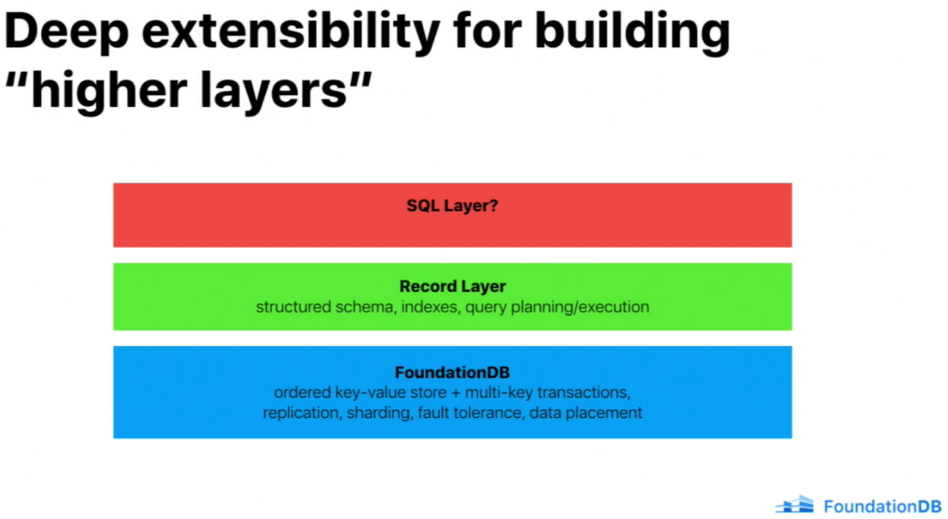
🔗Apple's Record Layer
The paper is located FoundationDB Record Layer:A Multi-Tenant Structured Datastore
Record Layer was designed to solve CloudKit problem.
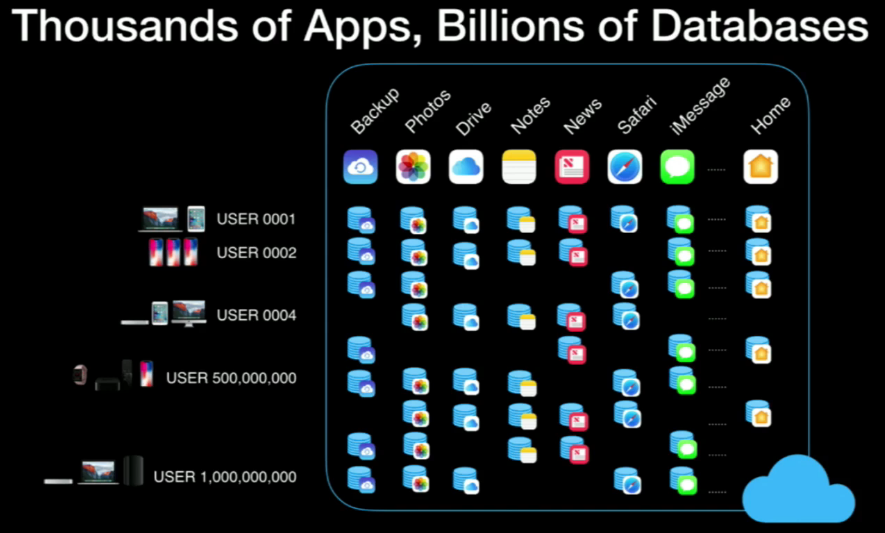
Record allow multi-tenancy with schema above FDB
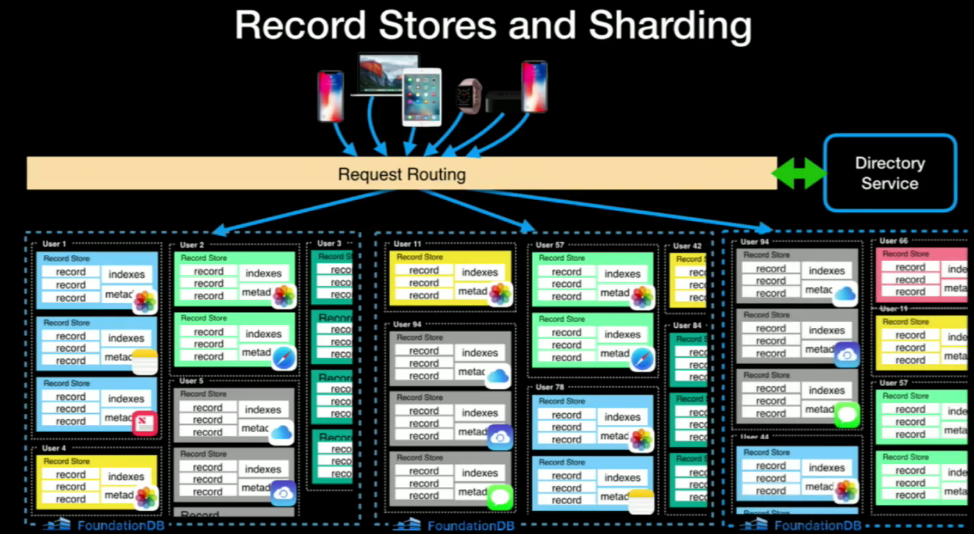
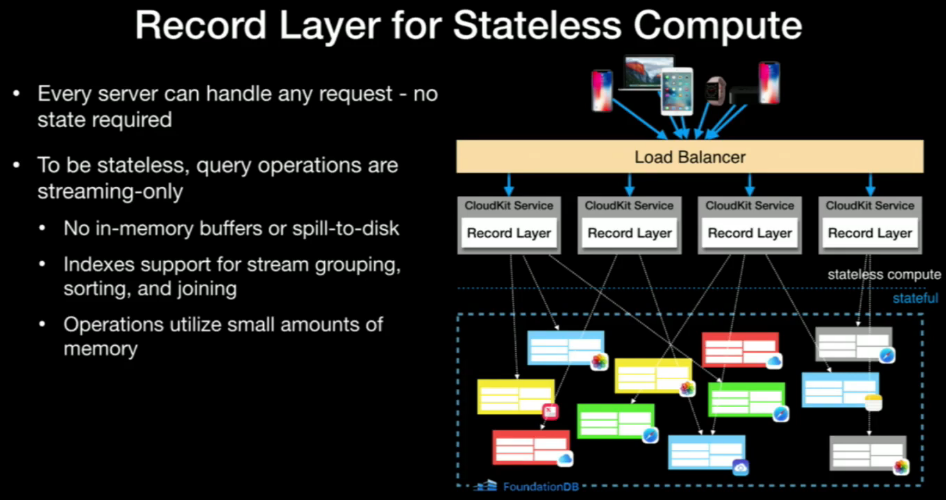
Record Layers is providing stateless compute
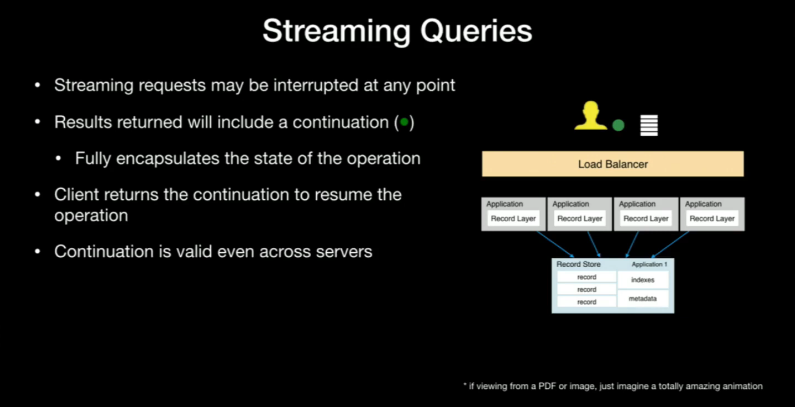
And streaming queries!
🔗Kubernetes Operators
🔗Overview of the operator


Upgrade is done by bumping all processes at once 😱


🔗Combining chaos-mesh and the operator
I played a bit with the operator by combining:
- FoundationDB/fdb-kubernetes-operator
- pingcap/go-ycsb
- pingcap/chaos-mesh
- PierreZ/fdb-prometheus-exporter
The experiment is available here.
🔗Roadmap
FoundationDB Release 7.0 Planning
Thank you for reading my post! Feel free to react to this article, I am also available on Twitter if needed.