Contributing to Apache HBase: custom data balancing
This is a repost from OVHcloud's official blogpost., please read it there to support my company. Thanks Horacio Gonzalez for the awesome drawings!
In today's blogpost, we're going to take a look at our upstream contribution to Apache HBase's stochastic load balancer, based on our experience of running HBase clusters to support OVHcloud's monitoring.
🔗The context
Have you ever wondered how:
- we generate the graphs for your OVHcloud server or web hosting package?
- our internal teams monitor their own servers and applications?
All internal teams are constantly gathering telemetry and monitoring data and sending them to a dedicated team, who are responsible for handling all the metrics and logs generated by OVHcloud's infrastructure: the Observability team.
We tried a lot of different Time Series databases, and eventually chose Warp10 to handle our workloads. Warp10 can be integrated with the various big-data solutions provided by the Apache Foundation. In our case, we use Apache HBase as the long-term storage datastore for our metrics.
Apache HBase, a datastore built on top of Apache Hadoop, provides an elastic, distributed, key-ordered map. As such, one of the key features of Apache HBase for us is the ability to scan, i.e. retrieve a range of keys. Thanks to this feature, we can fetch thousands of datapoints in an optimised way.
We have our own dedicated clusters, the biggest of which has more than 270 nodes to spread our workloads:
- between 1.6 and 2 million writes per second, 24/7
- between 4 and 6 million reads per second
- around 300TB of telemetry, stored within Apache HBase
As you can probably imagine, storing 300TB of data in 270 nodes comes with some challenges regarding repartition, as every bit is hot data, and should be accessible at any time. Let's dive in!
🔗How does balancing work in Apache HBase?
Before diving into the balancer, let's take a look at how it works. In Apache HBase, data is split into shards called Regions, and distributed through RegionServers. The number of regions will increase as the data is coming in, and regions will be split as a result. This is where the Balancer comes in. It will move regions to avoid hotspotting a single RegionServer and effectively distribute the load.
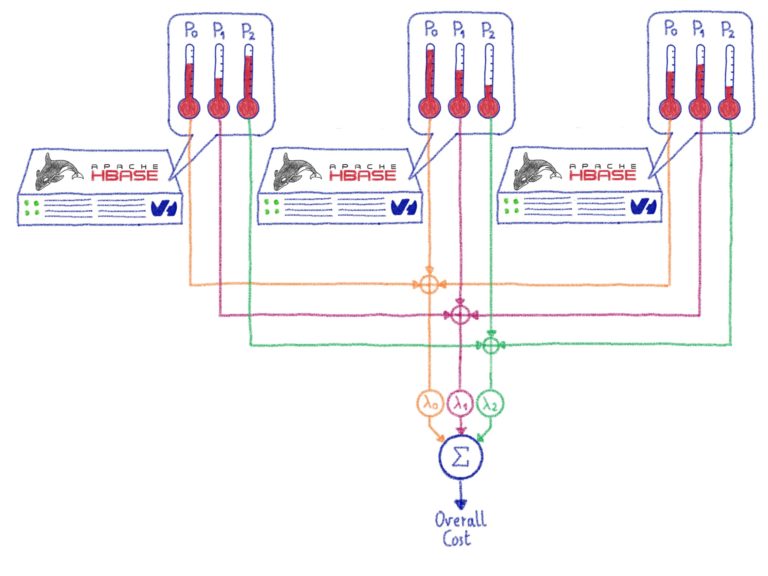
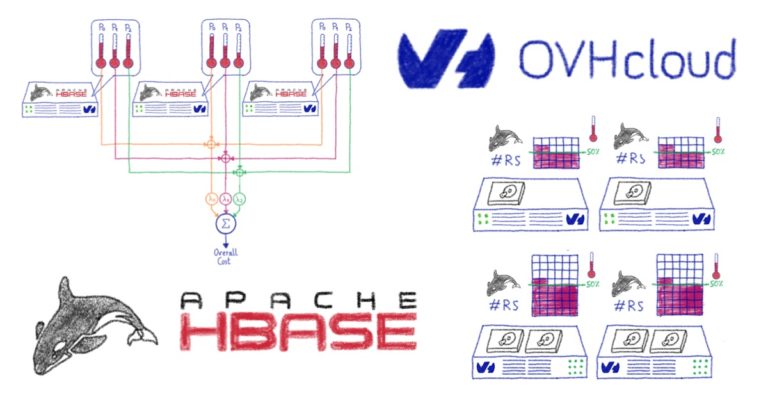
The actual implementation, called StochasticBalancer, uses a cost-based approach:
- It first computes the overall cost of the cluster, by looping through
cost functions. Every cost function returns a number between 0 and 1 inclusive, where 0 is the lowest cost-best solution, and 1 is the highest possible cost and worst solution. Apache Hbase is coming with several cost functions, which are measuring things like region load, table load, data locality, number of regions per RegionServers... The computed costs are scaled by their respective coefficients, defined in the configuration. - Now that the initial cost is computed, we can try to
Mutateour cluster. For this, the Balancer creates a randomnextAction, which could be something like swapping two regions, or moving one region to another RegionServer. The action is applied virtually , and then the new cost is calculated. If the new cost is lower than our previous one, the action is stored. If not, it is skipped. This operation is repeatedthousands of times, hence theStochastic. - At the end, the list of valid actions is applied to the actual cluster.
🔗What was not working for us?
We found out that for our specific use case, which involved:
- Single table
- Dedicated Apache HBase and Apache Hadoop, tailored for our requirements
- Good key distribution
the number of regions per RegionServer was the real limit for us.
Even if the balancing strategy seems simple, we do think that being able to run an Apache HBase cluster on heterogeneous hardware is vital, especially in cloud environments, because you may not be able to buy the same server specs again in the future. In our earlier example, our cluster grew from 80 to ~250 machines in four years. Throughout that time, we bought new dedicated server references, and even tested some special internal references.
We ended-up with differents groups of hardware: some servers can handle only 180 regions, whereas the biggest can handle more than 900. Because of this disparity, we had to disable the Load Balancer to avoid the RegionCountSkewCostFunction, which would try to bring all RegionServers to the same number of regions.
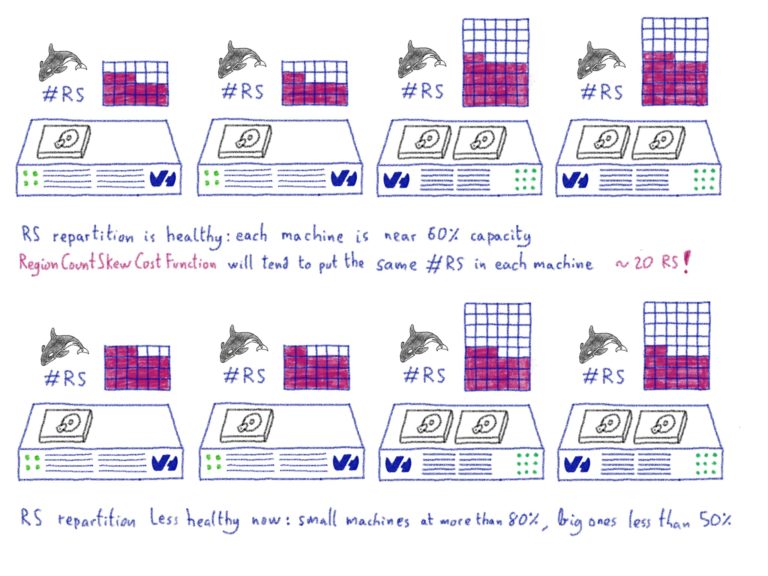
Two years ago we developed some internal tools, which are responsible for load balancing regions across RegionServers. The tooling worked really good for our use case, simplifying the day-to-day operation of our cluster.
Open source is at the DNA of OVHcloud, and that means that we build our tools on open source software, but also that we contribute and give it back to the community. When we talked around, we saw that we weren't the only one concerned by the heterogenous cluster problem. We decided to rewrite our tooling to make it more general, and to contribute it directly upstream to the HBase project .
🔗Our contributions
The first contribution was pretty simple, the cost function list was a constant. We added the possibility to load custom cost functions.
The second contribution was about adding an optional costFunction to balance regions according to a capacity rule.
🔗How does it works?
The balancer will load a file containing lines of rules. A rule is composed of a regexp for hostname, and a limit. For example, we could have:
rs[0-9] 200
rs1[0-9] 50RegionServers with hostnames matching the first rules will have a limit of 200, and the others 50. If there's no match, a default is set.
Thanks to these rule, we have two key pieces of information:
- the max number of regions for this cluster
- the *rules for each servers
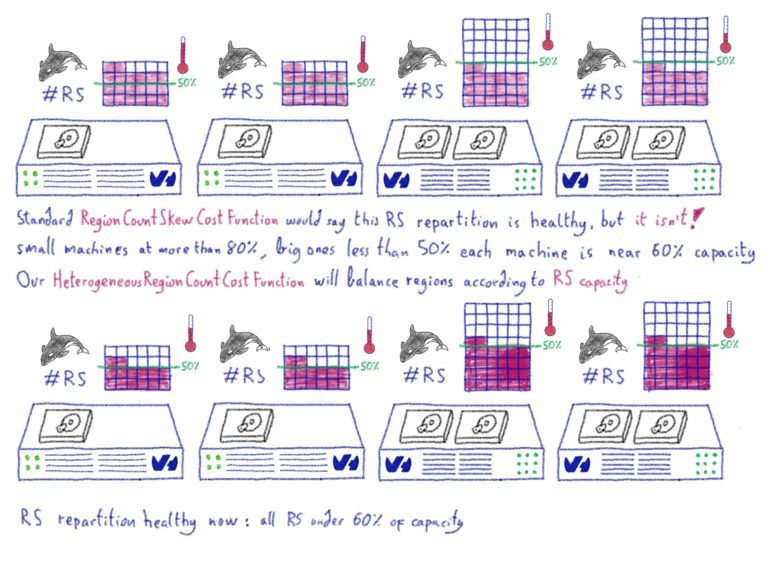
The HeterogeneousRegionCountCostFunction will try to balance regions, according to their capacity.
Let's take an example... Imagine that we have 20 RS:
- 10 RS, named
rs0tors9, loaded with 60 regions each, which can each handle 200 regions. - 10 RS, named
rs10tors19, loaded with 60 regions each, which can each handle 50 regions.
So, based on the following rules:
rs[0-9] 200
rs1[0-9] 50... we can see that the second group is overloaded, whereas the first group has plenty of space.
We know that we can handle a maximum of 2,500 regions (200×10 + 50×10), and we have currently 1,200 regions (60×20). As such, the HeterogeneousRegionCountCostFunction will understand that the cluster is full at 48.0% (1200/2500). Based on this information, we will then try to put all the RegionServers at ~48% of the load, according to the rules.
🔗Where to next?
Thanks to Apache HBase's contributors, our patches are now merged into the master branch. As soon as Apache HBase maintainers publish a new release, we will deploy and use it at scale. This will allow more automation on our side, and ease operations for the Observability Team.
Contributing was an awesome journey. What I love most about open source is the opportunity ability to contribute back, and build stronger software. We had an opinion about how a particular issue should addressed, but the discussions with the community helped us to refine it. We spoke with e ngineers from other companies, who were struggling with Apache HBase's cloud deployments, just as we were, and thanks to those exchanges, our contribution became more and more relevant.